|
Le signe © renvoie à la correction
L’objet de cet exercice est la réalisation d’un programme pour représenter graphiquement une fonction mathématique.
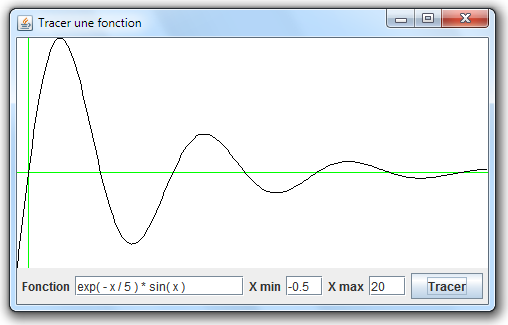
L’interface-utilisateur est représentée ci-contre. L’utilisateur saisit une fonction mathématique composée de constantes, d’occurrences de la variable x, des quatre opérateurs arithmétiques et de quelques fonctions transcendantes comme sin, cos, exp, log, etc., ainsi que les bornes XMin, XMax de l’intervalle de tracé. Quand il clique sur le bouton Tracer, la représentation graphique de la fonction apparaît.
Pour le codage interne de la fonction on utilisera les objets développés à l’exercice 4.5 (Expression, Constante, Variable, Addition, etc.). Il nous restera à faire :
Parlant familièrement, étant donné un langage, faire l’analyse d’un texte c’est dire s’il constitue une phrase correcte dans ce langage. Or, les phrases sont faites de mots. Il est donc pratique et efficace de reconnaître deux niveaux dans ce travail :
Souvent ce qui nous intéresse n’est pas l’analyse syntaxique du texte, mais sa compilation, c’est-à-dire l’extraction d’une information que ce texte porte. Sur le plan logique, cette extraction est consécutive à l’analyse syntaxique. Sur le plan pratique, elle est simultanée : l’analyse guide le travail du compilateur qui, en même temps, construit de proche en proche une structure codant en mémoire de ce que le texte signifie.
Ici, cela donnera : en même temps que notre analyseur reconnaît que le texte « exp(–x/5)*sin(x) » est syntaxiquement correct, il construit la structure de données (un arbre d’objets Expression) qui représente la fonction mathématique définie par le texte.
Analyse lexicale
Notre analyseur lexical sera un objet StreamTokenizer(1) prenant pour entrée une chaîne de caractères(2), le texte tapé dans le champ Fonction. Ainsi, le constructeur de la classe Analyseur ressemblera à ceci :
public class Analyseur {
private StreamTokenizer lexical;
public Analyseur(String texte) throws IOException {
Reader entree = new StringReader(texte);
lexical = new StreamTokenizer(entree);
lexical.ordinaryChar('/');
lexical.ordinaryChar('-');
...
}
...
}
Les caractères '/' et '-' doivent être indiqués comme étant ordinaires car autrement le premier serait traité comme le début d’un commentaire et le second comme une lettre (par défaut, un identificateur peut contenir des tirets).
L’analyseur syntaxique utilise l’analyseur lexical à travers des appels de sa méthode nextToken(). À partir d’une certaine position courante dans le texte (initialement le début du texte), cette méthode fait « avancer » l’analyseur d’autant de caractères qu’il le faut pour reconnaître une unité lexicale (c’est-à-dire un mot). Elle renvoie comme résultat un nombre entier conventionnel, qui est une des valeurs suivantes :
À tout moment, la variable ttype contient le résultat renvoyé par nextToken() la dernière fois qu’elle a été appelée.
Analyse syntaxique
À la base d’un analyseur syntaxique on trouve la syntaxe du langage visé. Une manière fréquente de spécifier cette dernière est la donnée d’une grammaire non contextuelle comme ceci :
expression –> [ '-' ] terme { ( '+' | '-' ) terme }
terme –> facteur { ( '*' | '/' ) facteur }
facteur –> 'nombre' | 'x' | '(' expression ')' |
( 'sin' | 'cos' | 'exp' | 'log' ) '(' expression ')'
Cette grammaire est faite de trois règles, dans lesquelles une convention typographique permet de distinguer :
Ces règles déterminent la grammaire d’un langage par la convention suivante : un texte est correct pour une règle si, de la gauche vers la droite, on y trouve les éléments indiqués par le second membre de la règle.
Par exemple, la première de nos règles dit qu’un texte est une expression correcte si et seulement si on on y trouve, de la gauche vers la droite : un signe moins ou rien, un terme (une autre règle précise ce qu’est un terme correct) et un nombre quelconque de couples formés d’un signe additif (c.-à-d. + ou –) et un terme.
On voit que cette grammaire définit bien le langage qui nous intéresse. En parlant vite, elle dit qu’une expression est une somme de termes, qu’un terme est un produit de facteurs et qu’un facteur est soit un nombre, soit la variable x, soit une expression entre parenthèses, soit enfin l’appel d’une des fonctions connues.
On convient enfin que le membre gauche de la première règle est le symbole de départ de la grammaire, c’est-à-dire celui qui qualifie la totalité du texte donné à analyser. Ainsi, pour notre analyseur, analyser un texte c’est reconnaître une expression.
Le travail de programmation à faire pour disposer d’un analyseur syntaxique correspondant à la grammaire ci-dessus consiste en l’écriture de trois méthodes correspondant aux règles de la grammaire, nommées donc reconnaitreExpression(), reconnaitreTerme(), reconnaitreFacteur() ou, plus simplement, expression(), terme(), facteur(). Le corps de chacune de ces méthodes se déduit du membre droit de chacune des règles, en supposant [et en faisant en sorte] que l’analyseur lexical est constamment positionné sur la première unité lexicale à examiner.
A titre d’exemple, voici la plus simple de ces trois méthodes (constatez comment ce code dérive de la règle de grammaire « terme –> facteur { ( '*' | '/' ) facteur } ») :
void terme() {
facteur();
while (lexical.ttype == '*' || lexical.ttype == '/') {
lexical.nextToken();
facteur();
}
}
Codage de l’expression
A partir d’un analyseur syntaxique correct, la construction d’une représentation interne de l’expression s’obtient en ajoutant quelques opérations aux méthodes formant l’analyseur, qui reste l’élément structurant du programme. Si on décide que les trois méthodes expression, terme et facteur doivent renvoyer comme résultat l’objet construit, voici ce que devient la méthode terme précédemment montrée :
Expression terme() { Expression resultat = facteur(); while (lexical.ttype == '*' || lexical.ttype == '/') { int operateur = lexical.ttype; lexical.nextToken(); Expression aux = facteur(); if (operateur == '*') resultat = new Multiplication(resultat, aux); else resultat = new Division(resultat, aux); } return resultat; }
Outre les trois méthodes expression, terme et facteur, pour chapeauter le travail il faudra une méthode analyser qui pourrait ressembler à ceci :
public Expression analyser() throws IOException, ErreurDeSyntaxe {
lexical.nextToken();
Expression resultat = expression();
if (lexical.ttype != StreamTokenizer.TT_EOF)
throw new ErreurDeSyntaxe("caractère inattendu à la fin du texte");
return resultat;
}
ErreurDeSyntaxe est une sous-classe de Exception définie pour la circonstance.
Outre la hiérarchie des objets Expression, récupérée de l’exercice 4.5, et la classe Analyseur que vous aurez développée et essayée indépendamment de l'interface graphique, il vous faudra écrire l'application principale, par exemple comme une classe Traceur (sous-classe de JFrame) contenant une classe interne PanneauDessin (sous-classe de JPanel). Le plus gros du travail concernera trois méthodes :
1. Le constructeur de la classe Traceur. Il doit créer le cadre principal de l’application, portant au centre le panneau où se fait le dessin (instance de PanneauDessin) et au sud un panneau avec trois étiquettes (JLabel), trois champs de texte (JTextField) et un bouton (JButton).
2. La méthode void actionPerformed(ActionEvent e) de l’objet ActionListener attaché au bouton Tracer. Cette méthode récupère les textes écrits dans les trois champs de texte, en signalant une erreur lorsqu’un des champs n’est pas garni, et affecte trois variables d’instance avec les nombres résultant de la conversion des textes Xmin et Xmax et, surtout, l’objet Expression résultant de la compilation du texte Fonction.
3. La méthode void paint(Graphics g) de la classe PanneauDessin. Cette méthode commence par déterminer les valeurs extrêmes Ymin, Ymax de la fonction f en calculant f(x) pour N valeurs de x régulièrement disposées entre Xmin et Xmax. On peut prendre, par exemple, N = 1000.

A partir des dimensions actuelles du panneau de dessin (données par les méthodes int getWidth(), int getHeight()) et des valeurs de XMin, XMax, YMin et YMax il faut déterminer les coefficients pour convertir les coordonnées utilisateur (x, y = f(x)) [vérifiant Xmin <= x <= Xmax, Ymin <= y <= Ymax] en coordonnées écran (u, v) [vérifiant 0 <= u <= width, 0 <= v <= height]. Voir la figure ci-contre.
Ensuite, la méthode trace la courbe en dessinant une ligne polygonale joignant les N points (x, f(x)) définis comme précédemment.
(1) La bibliothèque Java offre aussi des objets StringTokenizer mais, comme nous l’avons vu, ils sont beaucoup trop simples pour ce que nous voulons faire ici.
(2) Un StreamTokenizer est un analyseur (Tokenizer) basé sur un flux (Stream). Nous savons déjà que la source d’un flux est souvent un fichier ; nous voyons ici qu’elle peut être aussi une chaîne de caractères.